Abstract
3D vision-language grounding (3D-VL) is an emerging field that aims to connect the 3D physical world with natural language, which is crucial for achieving embodied intelligence. Current 3D-VL models rely heavily on sophisticated modules, auxiliary losses, and optimization tricks, which calls for a simple and unified model. In this paper, we propose 3D-VisTA, a pre-trained Transformer for 3D Vision and Text Alignment that can be easily adapted to various downstream tasks. 3D-VisTA simply utilizes self-attention layers for both single-modal modeling and multi-modal fusion without any sophisticated task-specific design.
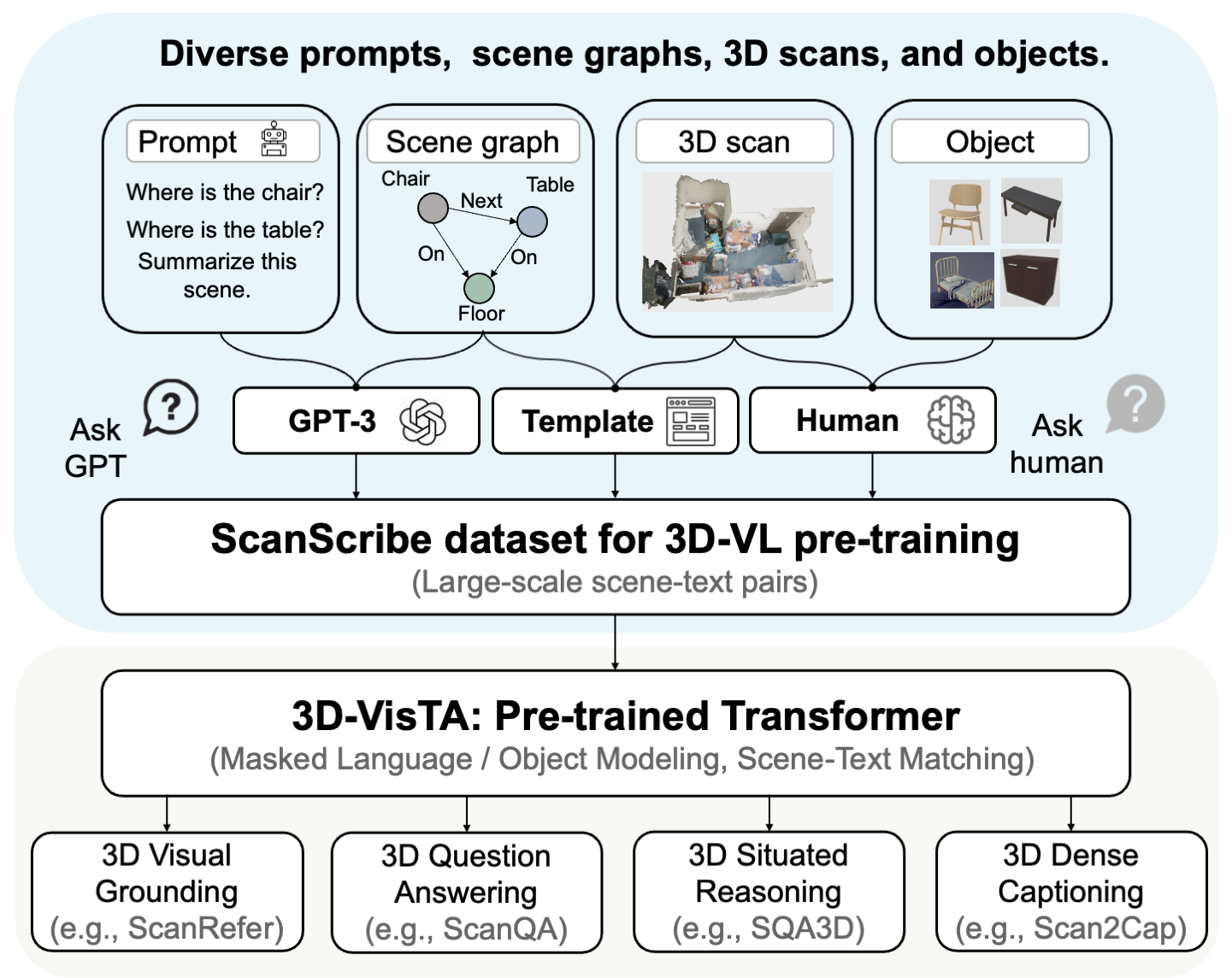
To further enhance its performance on 3D-VL tasks, we construct ScanScribe, the first large-scale 3D scene-text pairs dataset for 3D-VL pre-training. ScanScribe contains 2,995 RGB-D scans for 1,185 unique indoor scenes originating from ScanNet and 3R-Scan datasets, along with paired 278K scene descriptions generated from existing 3D-VL tasks, templates, and GPT-3. 3D-VisTA is pre-trained on ScanScribe via masked language/object modeling and scene-text matching. It achieves state-of-the-art results on various 3D-VL tasks, ranging from visual grounding and question answering to situated reasoning. Moreover, 3D-VisTA demonstrates superior data efficiency, obtaining strong performance even with limited annotations during downstream task fine-tuning.
Contribution
Our main contributions are
- 3D-VisTA model. We propose 3D-VisTA, a simple and unified Transformer for aligning 3D vision and text. The proposed Transformer simply utilizes the self-attention mechanism, without any complex task-specific design.
- ScanScribe dataset. We construct ScanScribe, a large-scale 3D-VL pre-training dataset that contains 278K 3D scene-text pairs for 2,995 RGB-D scans of 1,185 unique indoor scenes..
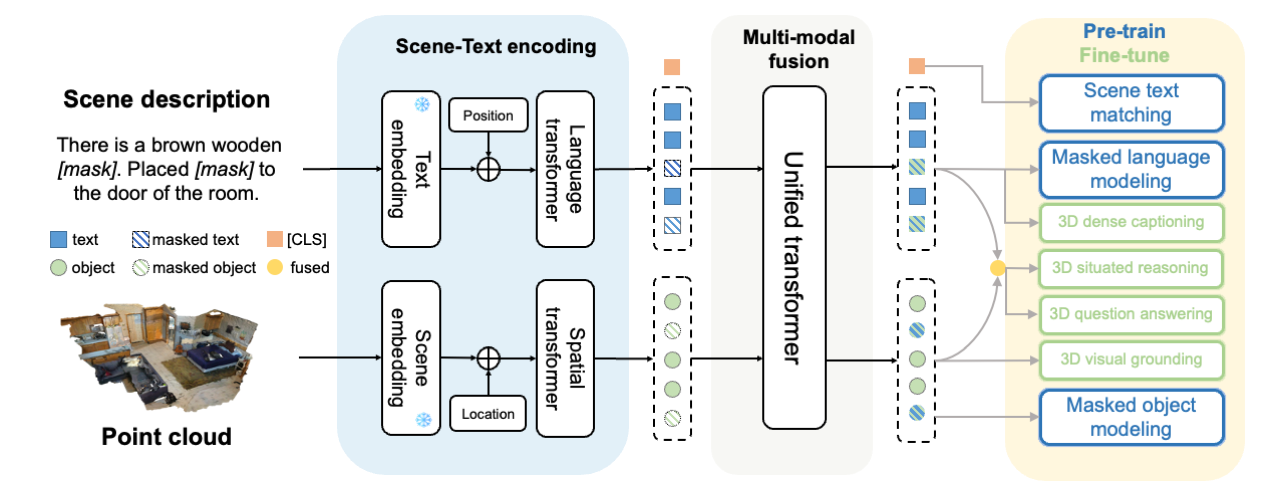
- 3D self-superised pre-training. We introduce a self-supervised pre-training scheme for 3D- VL, with masked language/object modeling and scene-text matching. It effectively learns the 3D point cloud and text alignment and further simplifies and improves downstream task fine-tuning.
- Performance. We fine-tune 3D-VisTA and achieve state-of-the-art per- formances on various 3D-VL tasks, ranging from visual grounding, question answering, and dense captioning to situated reasoning. 3D-VisTA also demonstrates superior data efficiency, obtaining strong results even with limited annotations.
 ScanScribe Dataset
ScanScribe Dataset
We collect RGB-D scans of indoor scenes from ScanNet and 3R-Scan. For the scans from ScanNet, we transform the text from existing datasets based on ScanNet into scene descriptions, including the question-answer pairs from ScanQA and the referring expressions from ScanRefer and ReferIt3D. For the scans from 3R- Scan, we adopt both templates and GPT-3 to generate scene descriptions based on their scene graph annotations. Ultimately, 278K scene descriptions are generated for the collected 3D scenes.

 3D-VisTA Model
3D-VisTA Model
3D-VisTA is a simple and unified Transformer for aligning 3D scenes and text. 3D-VisTA takes a pair of scene point cloud and sentence as input. It first encodes the sentence via a text encoding module and processes the point cloud via a scene encoding module. Then the text and 3D object tokens are fused by a multi-modal fusion module to capture the correspondence between 3D objects and text. 3D-VisTA is pre-trained using self-supervised learning and can be easily fine-tuned to various downstream tasks.
 Examples on 3DVL tasks
Examples on 3DVL tasks
Qualitative results on ScanRefer, ScanQA, and SQA3D. In (a,b,c,d,e), green and red denote the ground-truth and predicted object boxes, respectively. The results show that pre-training improves the understanding of spatial relations, visual concepts, and situations.
s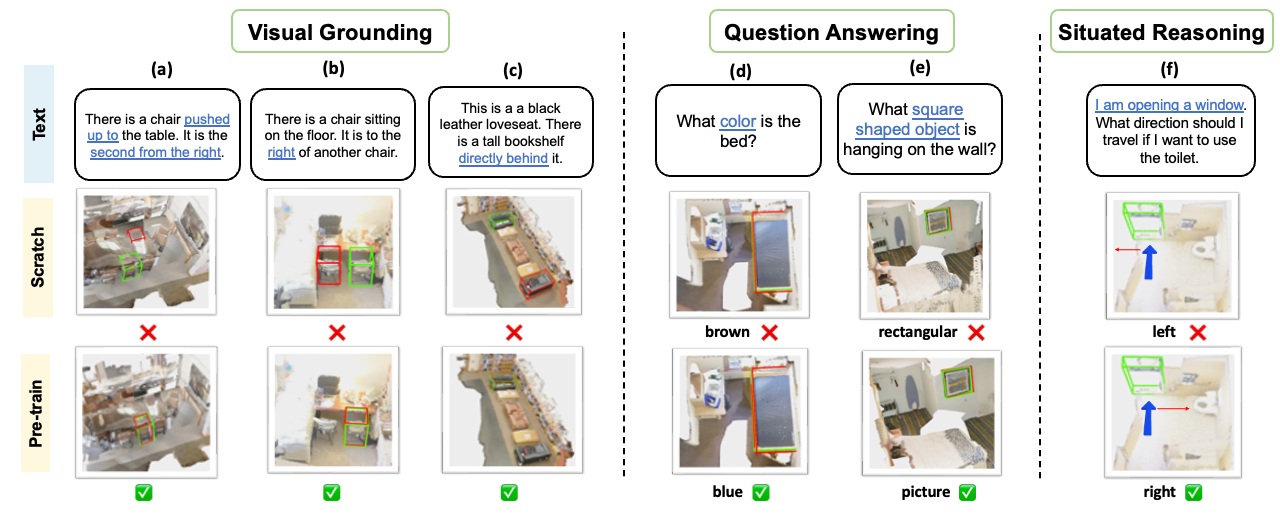
BibTeX
@inproceedings{3dvista,
title={3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment},
author={Ziyu, Zhu and Xiaojian, Ma and Yixin, Chen and Zhidong, Deng and Siyuan, Huang and Qing, Li},
booktitle={ICCV},
year={2023}
}